I work on a project, which is essentially just another recommendation engine. The data behind the engine also needs to be protected on the property level. Neo4j doesn’t natively support property level security so we had to come up with our own implementation of property level security.
Requirements
- Restrict per user the data that is returned to the web application
- Allow for partial matches when searching on property values
- Allow for searching on list properties – including partial match
- Need to return the full value of the partial match in the list
- Users have hundreds of possible security keys
- There is no single highest security key
- No one has all the security keys
Setup (at various times):
- Tinkerpop
- Neo4j Embedded 2.1.4
- Neo4j Embedded 2.3.2
- Neo4j Embedded 3.0.3
- Centos 6.x
- Java 8
First Attempt
The first attempt had the security key stored sidecar to the property:
- `node.property1`
- `node.property1_securityKey`
Lists were stored as JSON strings
- `[ { val1:securityKey1 },{ val2:securityKey1 },{ val3:securityKey2 } ]`
There were two properties on each node to indicate the minimum (read) and maximum (write) security keys needed to access the node. Updates to the node are only allowed if the user has the maximum security key, otherwise we don’t know if a value that’s being changed (value and security key are changed at the same time) the security key also without first accessing the graph. There was a mixture of =~ (security key regex) and IN [] (list of security keys) for checking the security keys in the Cypher statements.
Bad things – the security key on the edge had no relation to the security key of the related nodes. Also, all edges were labeled edge – although this got refactored during the migration to Neo4j 3.0.3.
Query
MATCH (n:NODE {prop3:”303”})-[e:PARENT_TO_PARENT]->(n2:NODE)
WHERE n.prop0_securityKey IN {keys} AND e.securityKey IN {keys} AND n2.securityKey IN {keys}
RETURN n2
Node
| “n” |
|---|
| nodeId:”78058” |
| uuid:”385ab6d5-c7d5-40d8-ac50-1b69e656d803” |
| prop0:”565” |
| prop0_securityKey:”094” |
| prop1:”483” |
| prop1_securityKey:”065” |
| prop2:”246” |
| prop2_securityKey:”045” |
| prop3:”303” |
| prop3_securityKey:”072” |
| prop4:”526” |
| prop4_securityKey:”072” |
| securityKey:”072” |
Results
The setup adequately restricts viewing of data. It’s slooooooow – we have to check keys on the node and the edge for each step of the traversal (traversals are typically 5 or more steps). We know what the combination of security keys are needed to see all the potential data in the system – ignore the checks if the user has it. Now the slowness is “invisible” for the developer, there’s more important features to add than worry about refining the security. Unit tests were written to ensure that the data is properly filtered. Out of sight, out of mind.
It’s so embarrassingly sloooooow
There has to be a better way – what happens when we use unique edge types for the security keys? Since every edge started out being called “edge”, we had to update them also. The combination of new edge types * max number of security keys was less than the Neo4j edge type limit, so it’s possible.
For this to work, the security key on the edge has to be the combination of the keys on both nodes as well as a possibly user defined security key on the edge. When traversing this will allow us to just follow edges, ignoring nodes along the way. To store properties, all properties with the same security key are stored on the same property node. In practice, this doesn’t result in too many property nodes per parent.
This is a really large number of edges – it can’t possibly work…
Test Setup
- 100,000 parent nodes
- 1 to 5 security keys per parent node
- 5 properties with random string values per parent node
String.valueOf(rand.nextInt(1000))- After creating all the nodes, sequentially go through the list of parent nodes and choose a random one to connect to the current one
- Queries written in Cypher
- All properties indexed (since we’re searching for them)
Query
MATCH (p:PROPERTY {prop3:”303”})<-[:HAS_PROPS_303|:HAS_PROPS_]-(n:NODE)-[e:PARENT_TO_PARENT_303|:PARENT_TO_PARENT_]->(n2:NODE)
RETURN n2
Node
| “n” |
|---|
| nodeId:”78058” |
| uuid:”385ab6d5-c7d5-40d8-ac50-1b69e656d803” |
| securityKey:”072” |
| “p” |
|---|
| prop3:”303” |
| prop4:”526” |
| securityKey:”072” |
Results
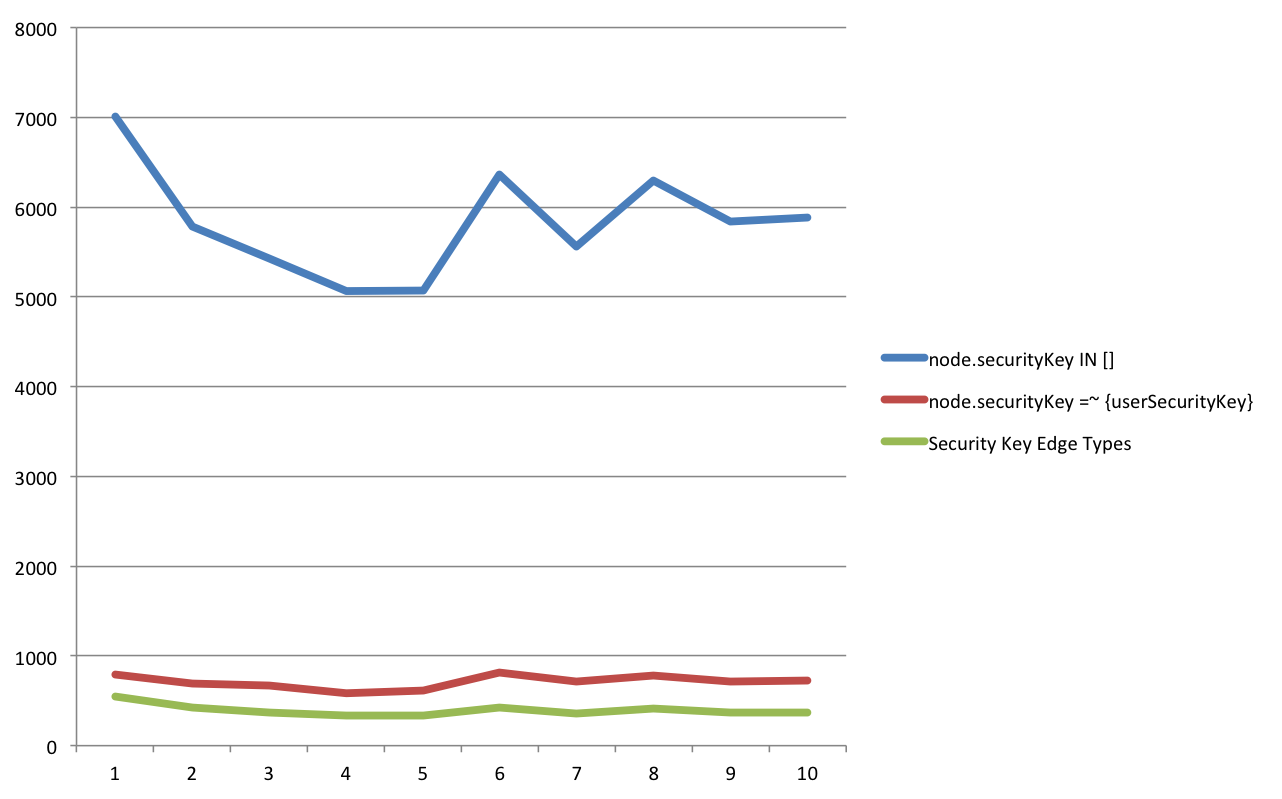
The edge types were a success – the queries checked an average of 103.1 unique security keys and returned an average of 8172 nodes.
node.securityKey IN []
Averaged 5831.3ms per runnode.securityKey =~ {userSecurityKeys}
Averaged 709.4ms per runEdge types
Averaged 395.4ms per run (~80ms each run for planning)
All edge types MUST exist in graph – after a certain point, there is a significant performance hit when checking non-existent edge types (using 3.0.2)
Graph Queries
Blue Line
UNWIND {propVals} AS p0
MATCH (n:NODE {prop0:p0})-[e:PARENT_TO_PARENT]->(n2:NODE)
WHERE n.prop0_securityKey IN {securityKeys} AND n2.prop0_securityKey IN {securityKeys} AND e.securityKey IN {securityKeys}
RETURN n2.prop0 AS prop0
Red Line
UNWIND {propVals} AS p0
MATCH (n:NODE {prop0:p0})-[e:PARENT_TO_PARENT]->(n2:NODE)
WHERE n.prop0_securityKey =~ {securityKeys} AND n2.prop0_securityKey =~ {securityKeys} AND e.securityKey =~ {securityKeys}
RETURN n2.prop0 AS prop0
Green Line
UNWIND {propVals} AS p0
MATCH (:PROPERTY {prop0:p0})<-[:HAS_PROPS_000|:HAS_PROPS_]-(:NODE)-[:PARENT_TO_PARENT_000|:]->(:NODE)-[:HAS_PROPS_000|:HAS_PROPS]->(p2:PROPERTY)
WHERE exists(p2.prop0)
RETURN p2.prop0 AS prop0
But….
There’s always a “but”. I was writing this presentation for a Neo4j User Group meeting and using my home laptop to reproduce the results. No matter what I did with Neo4j 3.1, I couldn’t reproduce the results. I knew for a fact that the results were real, the only thing to do was to retry with a bunch of versions of Neo4j – 3.0.2, 3.0.3, 3.0.9, 3.1.2, 3.2.0-alpha8.
Results
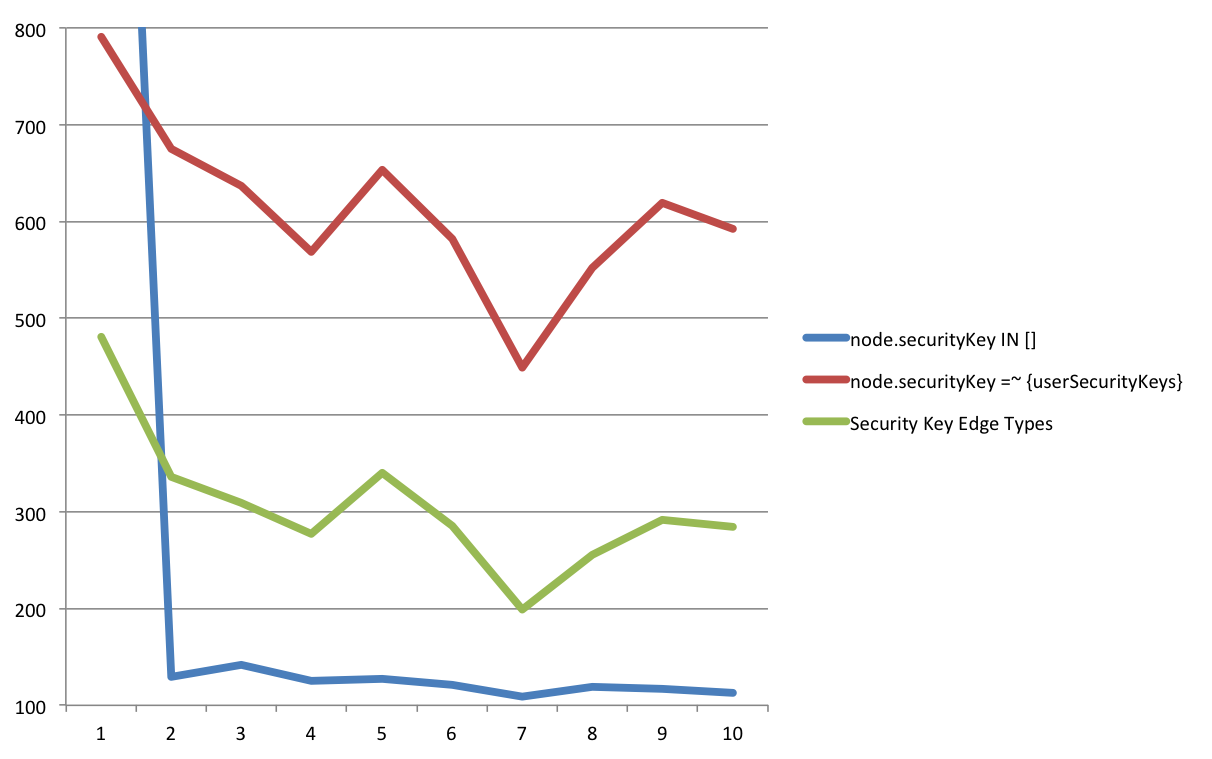
After re-running the tests with the various versions, it was discovered that there was a fix in 3.0.4 that allowed for the IN [] to run much faster. The edge type query is still about twice as fast as the regex query, but it’s no match for the list check. The new queries checked an average of 94.7 unique security keys and returned an average of 6467 nodes.
node.securityKey IN []
Averaged 122.4ms per run (283ms including first run)node.securityKey =~ {userSecurityKeys}
Averaged 611.9ms per runEdge types
Averaged 305.8ms per run
The queries were the same as before. The giant number for the first run of the blue query is because of the Cypher planning, afterwards it is consistently fast.
Searching in lists is still a problem – we still can’t easily get the match from the JSON value, other side effects from searching the JSON. There is no limit to the number of items that can be in the list so we can’t store them as node.listProp_1 … node.listProp_n. Storing the list values by security key in their own property node is our current best idea.
Some more testing was done to see if there was a difference between checking the security key on the edges versus on the nodes.
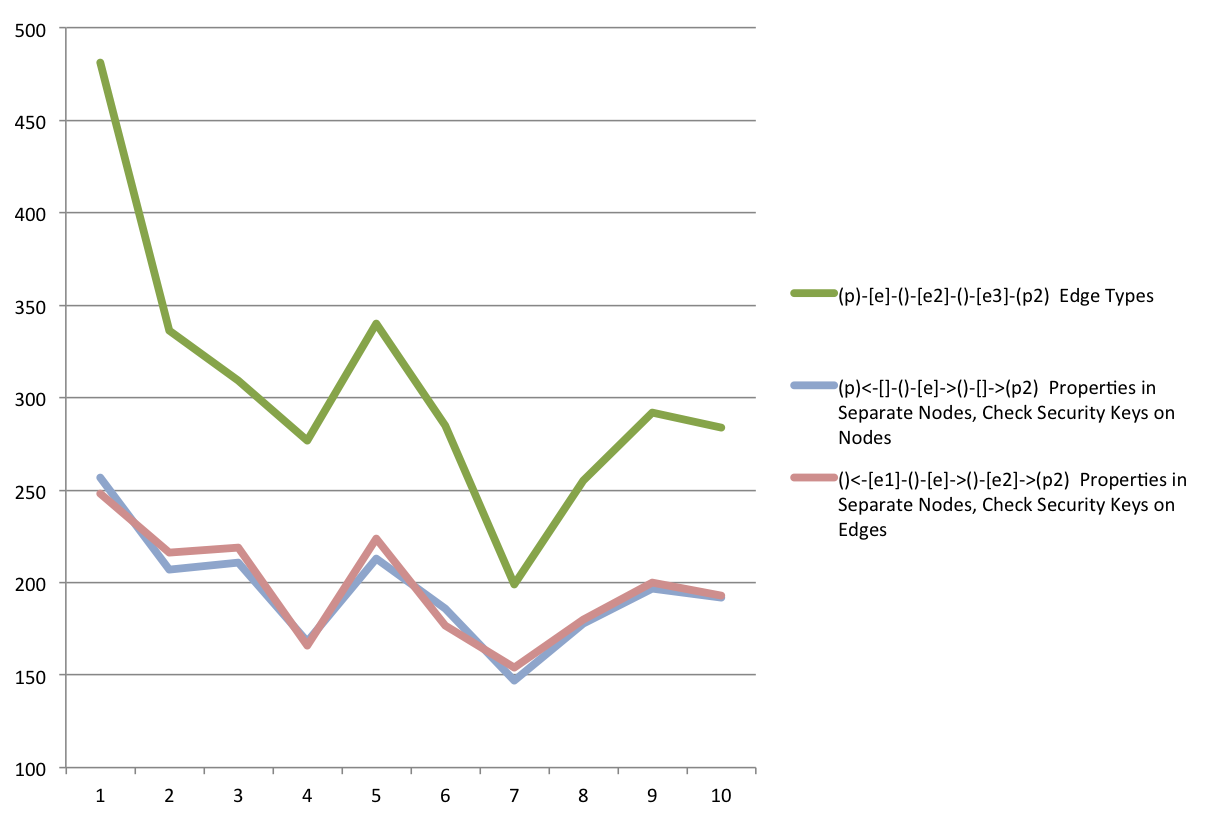
Results
The edge types were a success – the queries checked an average of 94.7 unique security keys and returned an average of 6467 nodes.
Edge types
Averaged 305.8ms per runCheck Security Key on Edges
Averaged 195.6ms per runCheck Security Key on Nodes
Averaged 197.7ms per run
Blue Line
UNWIND {propVals} AS p0
MATCH (p:PROPERTY {prop0:p0})<-[:HAS_PROPS]-(:NODE)-[e:PARENT_TO_PARENT]->(:NODE)-[:HAS_PROPS]->(p2:PROPERTY)
WHERE exists(p2.prop0) AND p.prop0_securityKey IN {securityKeys} AND p2.prop0_securityKey IN {securityKeys} AND e.securityKey IN {securityKeys}
RETURN p2.prop0 AS prop0
Pink Line
UNWIND {propVals} AS p0
MATCH (:PROPERTY {prop0:p0})<-[e1:HAS_PROPS]-(:NODE)-[e:PARENT_TO_PARENT]->(:NODE)-[e2:HAS_PROPS]->(p2:PROPERTY)
WHERE exists(p2.prop0) AND e1.securityKey IN {securityKeys} AND e2.securityKey IN {securityKeys} AND e.securityKey IN {securityKeys}
RETURN p2.prop0 AS prop0
Green Line
UNWIND {propVals} AS p0
MATCH (:PROPERTY {prop0:p0})<-[:HAS_PROPS_000|:HAS_PROPS_]-(:NODE)-[:PARENT_TO_PARENT_000|:]->(:NODE)-[:HAS_PROPS_000|:HAS_PROPS]->(p2:PROPERTY)
WHERE exists(p2.prop0)
RETURN p2.prop0 AS prop0
Checking the security key on nodes versus edges has a negligible difference, but were significantly faster than using edge types for security.
Conclusions?
If you don’t have to allow partial matches in a list value, don’t allow it. Even though there was a noticeable performance improvement to be gained by keeping non-list properties on the parent node, its value is questionable. For developers, it’s much easier to start searching for everything from the property nodes. For absolute speed, it’s fastest to limit property node values to lists, but there is a bunch of added complexity for figuring out where to start searching from.
For now, we’re storing all properties on property nodes and searching from there. All searchable properties also have a _searchable property next to it that’s lowercased so we can use CONTAINS and STARTS WITH for searching.
The source code for the test is available at:
Thanks to Jeff Wilson and James Morrison for the initial prototyping.





