Offline Automatic Modulation Recognition
Automatic Modulation Recognition (AMR) is a system designed to classify modulation schemes based on input in-phase and quadrature (I/Q) data. With the emergence of Deep Learning (DL), AMR has shown promising results in being able to perform using a paradigm of data-driven modeling schemes where the necessity of hand-engineered features is minimized. In efforts to build a suite of tools to enable Radio-Frequency Machine Learning (RFML) on low-SWAP platforms, Geon investigated the development and deployment of a DL-based AMR system into a Jetson TX2.
Dataset
Geon developed an AMR system in TensorFlow using a custom workstation equipped with a pair of Nvidia 1080Ti GPUs. The work here is primarily adopted from , which uses ImageNet architectures to perform over-the-air signal classification. DeepSig’s RADIOML2018.01A dataset is used in developing this work as it contains a collection of various modulation schemes of I/Q data across a wide range of SNR. A snapshot of the dataset’s total distribution across the 24 available target classes are shown below:
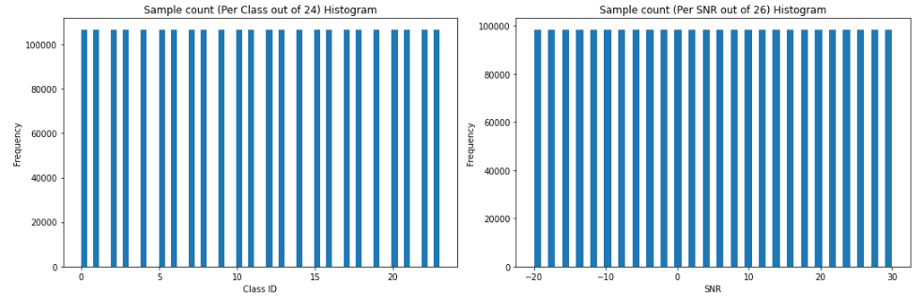
Figure 1: RADIOML2018A sample count distribution across classes and SNR
An even distribution of class samples across the SNR range facilitates balanced data suitable for training and testing. However, a visual snapshot of the modulation schemes across the SNR range show how much signal degradation can exist.

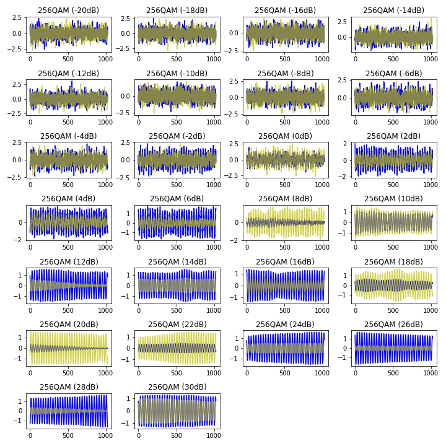
Figure 2: Random I/Q snapshots across the available SNR Range: 8PSK (left), and 256QAM (right)
Data Loading and Pipeline
The available RADIOML2018A dataset was broken into smaller chunks to relieve memory constraints during development. TensorFlow’s TFRecords was used to write out data shards that worked with the tf.data API during training and testing in the ML pipeline. Extraction, Transform and Load (ETL) concepts are easily facilitated here for pre-processing steps such as augmentation, perturbation, and normalization, and pipeline-specific actions such as pre-fetching, shuffling, and batching.
Model Building, Training and Testing
Geon applied similar concepts detailed in [1] for building the model architectures. The input data was in the form of a NxM n-d array, where N=2, representing the I and Q data dimensions, and M=1024, representing the total number of I/Q samples for a given snapshot. The initial deep learning architecture was a standard CNN using a series of convolutional and maxpool layers, with further investigations using layers and functions such as batch normalization, scaled exponential linear units and ResNet modules which are not detailed here. Conceptually, the I/Q snapshots are treated as input images where the I and Q dimensions are provided with an equal number of samples in a short window of time, relative to the sampling frequency. Since these snapshots present the transient nature of the signal, the hope is to model the relationships of these features such that they can confidently point back to a particular modulation scheme, regardless of distortions and additive noise.
The AMR system was designed as a multi-target classification task with a categorical-cross entropy learning function. Both the adam and stochastic gradient descent (SGD) were used with and without a learning schedule, and learning metric trends were reviewed using tensorboard. The data was split in approximations of 70%/10%/20% for training, validation and testing, respectively, across the available TFRecord shards in a k-fold split. A snapshot of a completed, single fold is shown below.
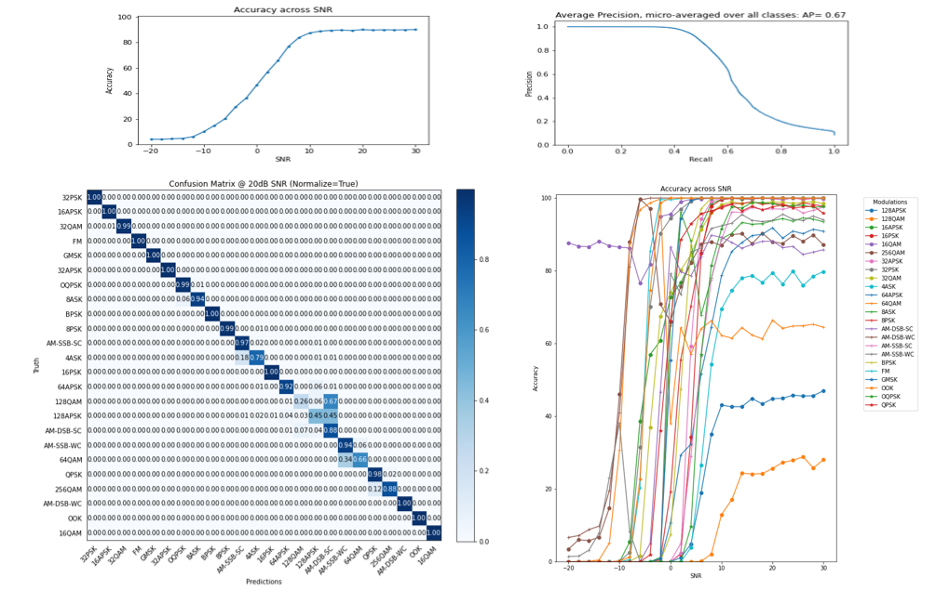
Figure 3: Weighted Accuracy Per SNR (top left), Confusion Matrix @20dB SNR (bottom left), Precision and Recall (top right), Top-1 Accuracy for per Target Class per SNR (bottom right)
The top left plot represents the weighted classification accuracy across all target modulation schemes. It can be shown that performance excels at 10dB SNR and above but starts to significantly degrade as SNR ranges fall towards 0dB and below. The ability to classify signals at -10dB and below is essentially non-existent. These results can be expanded with greater detail by observing the sensitivity metrics and the individual Top-1 scores of the top and bottom plots on the right-hand side, respectively. Significant details in performance can be seen as the modulation order increases (128APSK and 128QAM). An unwanted result is shown with 16QAM where it seems to starkly outperform all other individual modulation classifications at extremely low SNR values. However, this is the result of a system that being unable to properly classify signals and instead choosing a specific target class regardless of the input at these levels of noise. This could suggest that the representative input at low SNR does not provide any distinguishing features to be learned, or that during training, the ML model could not converge with the learning capacity to perform at lower SNR.
Looking forward, additional experiments could be conducted to address some of these issues when working within the confines of the current dataset. One method would be to train a set of smaller models representing “groups” of modulation schemes (PSK, APSK, ASK, QAM), to facilitate optimization in a smaller space. This could reduce the complexity involved in training a single model that attempts to be a “jack-of-all-trades” system, especially when more detail and understanding of the underlying signals are required.
Techniques to address noise can also be considered in efforts to clean up the quality of the data prior to training and testing. For instance, a noise-autoencoder could “transform” inputs into an ideal representation of the signal of interest. To improve the feature space, additional signal-processing related features could be added, or larger/shorter contexts of I/Q data samples could be used in parallel (only 1024 sample snapshots were used here), and inputs such as Time-Frequency representations could be used to augment or replace the inputs to the ML models.
Finally, collection and use of over-the-air data will introduce distortions and variables more relevant to an operational environment and are compelling to use for training models. Interfacing with hardware on operational platforms will require ways to address issues such as channelization, sampling rate, frequency offsets, and I/Q imbalance.
Deployment into the Jetson TX2
The model trained in the workstation was converted into a TensorRT version, which is an optimized graph that can improve inference efficiency and latency. The converted AMR model was deployed on the Jetson TX2 as a Docker container with the intent that individual RF and ML services would communicate and process RF data accordingly. Docker-compose was used to stand up the RF client as a publisher and the AMR system as a subscriber. When the RF client received data, it was dumped into a shared volume and a message was broadcast using ZeroMQ (ZMQ). Appropriate services, such as the ML module, listen for broadcasts and then perform inference on available data in a shared volume. A simulation was executed in which received RF data was stored, processed, and analyzed. The result was an end-to-end pipeline with modules allowing data ingestion, processing, and inference, with hooks to further enable logging and post-processing analysis.
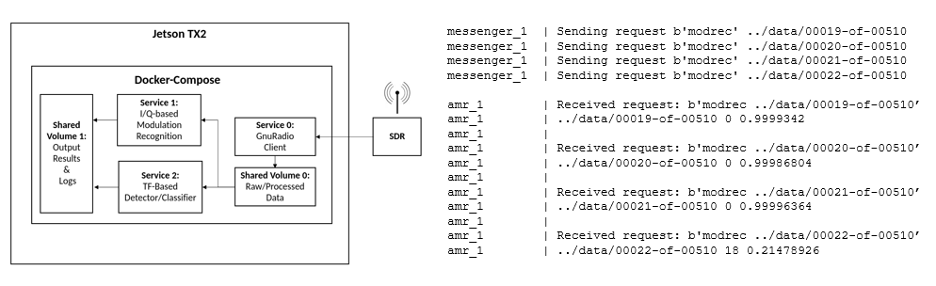
Figure 4: RFML Concept in the Jetson (left), Dockerized RF/ML container interaction (right)
Lessons Learned
There were a number of issues discovered with respect to meeting dependency requirements between the development setup in the offline workstation and the Jetson. For instance, the GPU workstation uses a specific version of TensorFlow and it was discovered that the NVIDIA L4T images (for the Jetson) support a different version of software packages. Resolving the necessary dependencies across TensorFlow, TensorRT, CUDA, cuDNN, the GPU, and the OS required updates and/or rollbacks to ensure GPU-based experiments properly functioned. This effort consumed far more time than expected and included troubleshooting as mismatches on one layer of abstraction required changes to previous ones.
Looking Forward
Geon is conducting further work to augment its RFML suite. For instance, Geon has developed a container with a GNU Radio Framework installed and custom hierarchal blocks providing I/Q data and Time-Frequency representations such as spectrograms. This data is processed downstream to accomplish tasks such as wireless protocol identification. Future work involves additional testing to improve model robustness and a pipeline to seamlessly deploy new models.





